Структури даних
Контейнерами у комп’ютерній науці називають класи, структури даних та інші типи даних, які можуть містити у собі колекції деяких елементів. У реальному житті це: ящики, сумки, банки та інше. Навіть стопки тарілок є контейнерами, адже містять декілька елементів — тарілок.
Окрім класів, контейнерами є структури даних — спосіб організації даних разом з набором доступних над нами операцій. До основних структур даних у Python належать: списки, кортежі, множини і словники.
Впорядкованість структури даних визначає, чи знаходяться її елементи у певному визначеному порядку, чи у довільному розташуванні.
Мутабільність (змінність) описує, чи може певний об’єкт змінювати свої характеристики. Немутабільні типи можна порівняти з константами — їх значення (та властивості) залишаються однаковими за будь-яких умов. Втім, слід розуміти, що у багатьох випадках можна видалити немутабільний елемент і створити новий, з аналогічними, але зміненими властивостями.
Індексованими є структури даних, у яких кожен впорядкований елемент має індекс. Найчастіше це ціле число. Якщо “індексом” є не число, можна називати це скоріше ключем.
Список
Списки (lists) у Пайтоні є впорядкованими мутабільними індексованими структурами даних. Вони також можуть мати однакові елементи у кількох екземплярах. Елементи записують у квадратних дужках через кому.
aList = ["cat", "dog", "pheasant", "cat", "vole"]
Для доступу до елементів списку можна використовувати числові індекси, теж починаючи з 0. Також, у Python можна використовувати від’ємні індекси (звичайно, -0 не можна, тому починаючи з -1) для доступу до елементів з кінця.
aList[1] # dog
aList[-1] # vole
Розшарування (зріз)
У Python існує операція розшарування, яка дозволяє отримати зріз списку — його частину від одного до іншого індексів як новий список. Так само, як у range, початковий індекс включний, а кінцевий береться виключно. Використовується для цього двокрапка.
Будь-яке із значень можна пропустити. Від’ємні індекси дозволяються за однієї умови. Важливо: ця операція працює лише зліва направо, тому якщо кінцевий індекс буде меншим, ніж початковий, буде повернено порожній список!
aList[1:3] # ["dog", "pheasant"]
aList[-4:-1] # ["dog", "pheasant", "cat"]
aList[3:] # ["cat", "vole"]
Тим не менш, є спосіб зробити обернений зріз — справа наліво. Для цього можна вказати крок -1 як 3-й аргумент. Це, до речі, один із способів отримати обернений список: залишити порожніми початковий та кінцевий індекси, а кроком -1 пройтись у зворотньому порядку. Безумовно, крок може бути й іншим довільним числом.
aList[-1:-4:-1] # ["vole", "cat", "pheasant"]
aList[::-1] # ["vole", "cat", "pheasant", "dog", "cat"]
Методи роботи з елементами
Для знаходження довжини списку є метод len(<список>): len(aList) # 5.
Якщо потрібно вставити елемент за довільним індексом, зсуваючи решту елементів праворуч від нього, можна використати insert(<індекс>, <значення>): aList.insert(2, "mouse").
Для додавання елементу в кінець, є append(<елемент>): aList.append("dog").
Видалення за індексом через pop(<індекс>), а видалення конкретного значення за допомогою remove(<значення>): aList.remove("vole"), aList.pop(2).
Сортування за зростанням — sort(): aList.sort(); за спаданням — sort(reverse=True): aList.sort(reverse = True). Навіщо в аргументах знак “дорівнює” буде розказано у розділі про функції :)
Створити копію списку — copy(): aList.copy(). У першому розділі Основ було сказано, що звичайне присвоювання створило б просто посилання, тому для копіювання масиву потрібен окремий метод.
Порахувати кількість певного елементу можна за допомогою count(<елемент>): aList.count("cat").
Кортеж
Кортежі (tuples) є впорядкованими немутабільними індексованими структурами даних, що дозволяють дублікатні значення. Уявити їх можна фактично як незмінні масиви, а замість квадратних дужок у них круглі.
aTuple = ("cat", "dog", "pheasant", "cat", "vole")
Функція довжини len(), як Ви могли помітити, є окремою вбудованою функцією, а не методом списків, тому є універсальною для багатьох типів даних. Більшість операцій з кортежами аналогічні тому, як виконувались зі списками, однак пам’ятайте, що додавати та змінювати елементи кортежів не можна.
Множина
Множини (sets) — це невпорядковані немутабільні структури даних, що не дозволяють декілька копій однакових значень. Записуюють у фігурних дужках. Враховуйте, що True та 1 вважаються однаковими у множинах, як і False та 0, тому булеві значення не будуть додані на користь чисел.
aSet = {"cat", "dog", "pheasant", "cat", "vole"}
Так як цей тип не є індексованим, то з елементами можна виконувати лише дві операції: ітерацію (наприклад, циклом for) та перевірку на наявність елемента оператором in.
Втім, можна додавати нові елементи до множини методом add(<елемент>): aSet.add("badger").
Для видалення елементів є два методи, remove та discard. Перший виведе помилку, якщо елемента не було у множині, а другий ні. aSet.remove("cat"), aSet.discard("turtle")
Математичні операції
Так як множини є математичним поняттям, то до них можна застосовувати математичні операції з множинами.
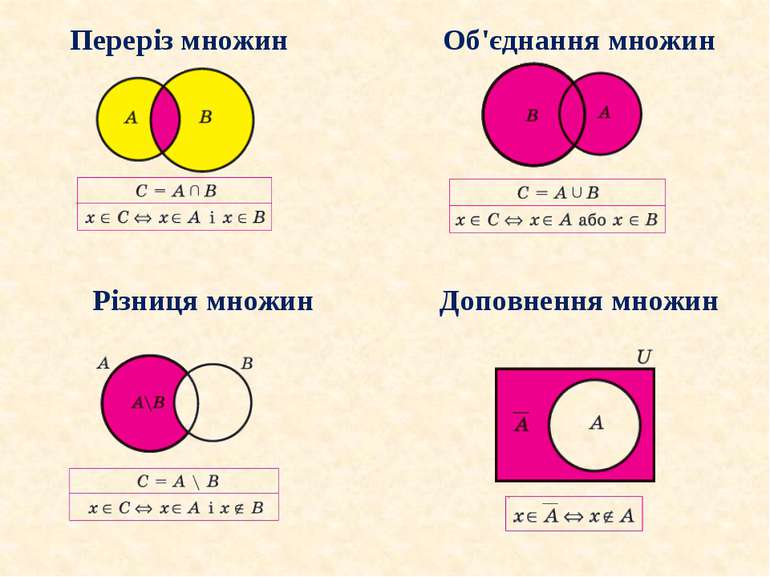
У Python ці операції є методами з відповідними назвами англійською. Вони повертають нові множини, що є об’єднанням a.union(b), різницею a.difference(b) або перетином a.intersection(b) множин a і b відповідно.
Словники
Останнім із базових чотирьох типів є словники (dictionaries). Це особливий тип даних, який дозволяє зберігати елементи у вигляді пар “ключ-значення”. Спрощено, це як списки, у яких замість напередвизначених індексів можуть бути будь-які із базових значень. Якщо Ви зустрічались з форматом файлів JSON — словники це його втілення у Пайтоні. Словники зручні для зберігання підрахунку об’єктів або для ієрархічних структур даних.
Записують словник у фігурних дужках, вказуючи елементи у вигляді <ключ>:<значення> через коми. Писати можна як у рядок, так і у кілька рядків для зручності читання.
aDict = {
"яблук": 8,
"груш": 5,
"апельсинів": 12
}
Доступ до значень здійснюється через квадратні дужки за ключем: aDict["груш"].
Можна отримати список ключів або значень окремо, наприклад, для роботи над словниками циклами: aDict.keys() та aDict.values() відповідно.
Оператор in перевіряє наявність ключа у словнику, а не значення. Методи pop(<ключ>) та copy() працюють і для словників теж.